A week or so ago, I saw this message from the RAID controller on my Dell T7600, which is my main machine:

I figured either the drive would fail completely or it wouldn’t. I could replace it before it failed or wait for it to fail, which might be a long time. That didn’t sound like a hard one. I waited.
Yesterday, it failed completely:

I probed for the details:
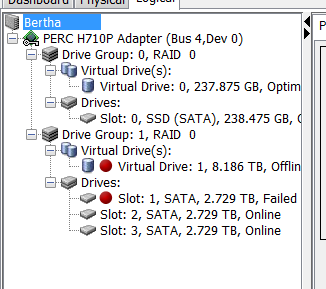
I got this warning:
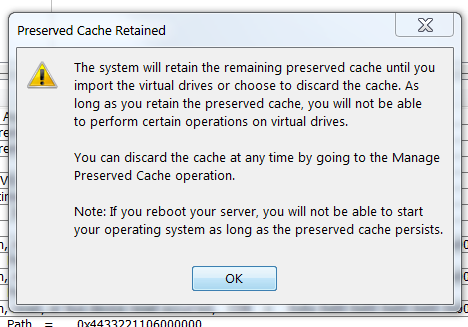
Sounds ominous, huh? There was no way to delete the cache from the MegaRAID Windows app. I called Dell. The tech said the only way to do that was from the MegaRAID BIOS.
The Dell tech support guy suggested unplugging and reseating the disk. Can’t hurt, might help, but I was ready with replacement disks. Disks? The array with the failed disk was a 9TB striped array (RAID 0) consisting of 3 3TB disks. I figured I’d upgrade the disks since I’d have to do a complete restore anyway.
I got some help to get the big heavy computer moved to a table where I could work on it. It was easy to get the side cover off. There was a big latch; one pull and the cover came right off. But I couldn’t find the disks. Were they behind the motherboard? No, that was where the power supply was. Were they accessible from the front? Probably, but how to get the front panel off? I was stumped. I was even considering reading the manual when I noticed a sticker on the inside of the side cover with pictograms showing how to get the front panel off.
With the front panel out of the way, there were the drive bays, nicely numbered – thank you, Dell. Bay 0 was the SSD, which – knock on wood – hadn’t broken. Bay 1 was the failed drive, and bays 2 and 3 held the working members of the failed array. I pulled the bad drive, and looked at the black plastic carrier to figure out how to get the disk out of the carrier. There were four stainless steel cylinders that fit into screw holes on the disk. They were held in the carrier by rubber bushings. I tried to pull out one of the bushings, but it didn’t want to come.
I know I’ll lose points for this, but I admit I downloaded and read the manual. Turns out you’re supposed to flex the plastic carrier far enough that the steel cylinders pop out of the drive. Without the manual, I’d never have the nerve to torque the plastic that far. The disk popped out.
Putting the new disk in the carrier wasn’t easy. The manual said that you could just bend the carrier, but I was afraid I’d break it. I took a dime and pushed the bushing nearest the front of the carrier, whre it’s hardest to bend, out a bit. Then I slipped the drive into the pins on the other side, torqued the carrier to get the other back pin in, and lined up the pushed-out pin. Then all I had to do was lean on the pushed-out pin with a screwdriver, putting it back in place.
I looked around for a 6 TB drive, but couldn’t find one. I installed 3 4TB Seagate drives (the failed drive was a Seagate), and told the RAID controller to make two of the drives into a mirrored array (RAID 1), and configure the other one as just a disk. I ordered a 6 TB enterprise-class Seagate drive from Newegg. I figure, with any kind of luck at all, it’ll get here before I can get all the data back on the 4 TB mirrored array, then I can install it where the 4 TB unmirrored disk is now.
The drives are now initializing – which looks like it will take about nine hours – and then I can start the restoration. It’ll probably take a few days to get everything running again. With this much data, everything takes a long time.
In ten years, somebody will read this blog and marvel that people like me stored data on rusty spinning platters.
It’s longer than ten years but in my retail pharmacy I was cutting edge using TWO 5 1/4 ” disks to hold the data for the Apple IIe labelling program. Strange that only quite recently we have started to moved away from spinning discs to hold our data, like batteries progress has been relatively slow in those areas, other than capacity.